Full-text search architecture
The full-text search feature uses the Solr search server and Lucene information retrieval library technologies. The next figure shows the key software components that comprise the full-text search implementation. These components are described in the next sections.
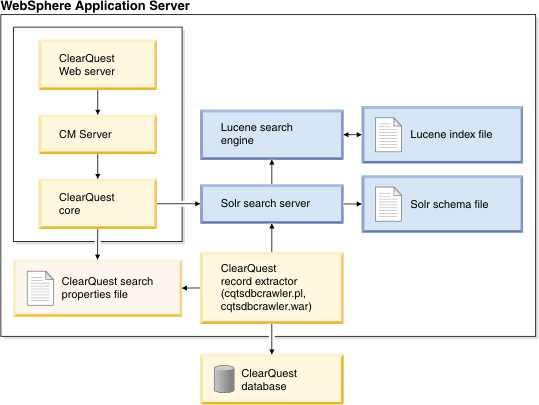
Solr search server
The Solr search server is the underlying full-text search engine used by ClearQuest. Solr is installed under and managed by WebSphere® Application Server. Solr sits on top of the Lucene search engine and provides convenient access for configuring, indexing, searching, and administering Lucene and its index. For more information about Solr, go to http://lucene.apache.org/solr/.
Solr schema file
The Solr schema file specifies the fields that Solr indexes. You configure the Solr settings based on your Rational ClearQuest schema.
Lucene search engine
The Lucene search engine is an open-source information retrieval library supported by the Apache Software Foundation and released under the Apache Software License. For more information about Lucene, go to http://lucene.apache.org/java/.
Lucene index file
The Lucene index file is the cornerstone of the Lucene information-retrieval library technology. The index is created by the Rational ClearQuest record extractor. The index is updated by commands sent from the record extractor to Solr, which in turn passes these commands on to the Lucene search engine.
Rational ClearQuest record extractor
The Rational ClearQuest record extractor is installed as two components: a component running under WebSphere Application Server and a command-line tool. While the software that comprises these two components is identical, their use differs.
The command line record extractor provides batch extraction of Rational ClearQuest records. It is started by the administrator, usually once, to extract existing records from Rational ClearQuest and send them to Solr for Lucene to index. This mode of operation is called batch mode record extraction.
The record extractor that functions as a WebSphere Application Server component provides continuous updates to the Lucene index. As new Rational ClearQuest records are added, modified, or deleted, the record extractor sends these records to Solr for Lucene to index. This mode of operation is called update mode record extraction. Once a record is indexed by Lucene, it is available for searching by using the Rational ClearQuest Web full-text search user interface.